Привет, эта глава книги устарела
Сейчас я развиваю новую версию книги «Как делать продукт», где ты найдешь материалы по текущей версии методологии Advance JTBD.
Если хочешь получать новые главы книги, прикладные инструменты и полезные материалы — подписывайся на бесплатный Telegram-бот.
Допустим, мы развиваем агентство долгосрочной аренды загородной недвижимости по всей России. Мы хотим найти сегмент для которого развивать услуги и продукты нашего агентства.
Гипотеза работы, которую мы выполняем для клиентов:
- когда у меня семья с детьми
- хочу часть времени жить с семьёй ближе к природе
- чтобы отдыхать от города, лучше восстанавливаться на выходных
Мы решили провести JTBD-исследование для поиска сегмента с людьми, которые уже выполняют эту работу. То есть ищем людей, которые владеют такой недвижимостью или арендуют и часть времени живут там. В каждой итерации исследования мы будем проводить по 16 интервью.
Первый типичный сценарий: нашли не тех респондентов

Периодически бывает так, что искали людей, которые владеют или арендуют загородную недвижимость и часть времени живут там, но при поиске респондентов совершили ошибки и нашли людей, которые не владеют/не арендуют недвижимость и не живут там.
Что делаем в такой ситуации: изучаем где именно совершили ошибку и повторяем итерацию поиска респондентов чтобы не совершить ошибку второй раз.
Второй типичный сценарий: нашли людей, которые выполняют работу редко или выполнение работы не важно для них
Мы не совершили ошибку во время поиска респондентов. Действительно, все люди с которыми мы провели интервью, часть времени живут в загородных домах, но они:
- не владеют и не арендуют, живут в доме семьи. Для нас это сильный сигнал что этот человек из целевого сегмента, так как он не платит за выполнение работы.
- владеют или арендуют, но живут очень редко, выезжают 3-4 раза в год. На вопрос о важности работы: «насколько важно по 10-балльной шкаоле для вас жить с семьёй часть времени на природе, где 10—забота о безопасности ваших близких», они отвечают 3. Низкая частотность и низкая важность для нас сигнализирует о том, что врядли они станут нашим целевым сегментом.
Что делаем в такой ситуации: корректируем исходную гипотезу работы по тому сколько дней в году респондент живёт за городом и при поиске респондентов ищем тех, кто владеет или арендует недвижимость.
Третий типичный сценарий: всех понемногу
Это самый часто встречающийся сценарий: среди 16 респондентов есть и ошибочно найденные и те, кто выполняет работу редко или выполнение работы не важно для них и те, кто часто выполняет интересную для нас работу и выполнение этой работы важно для них.
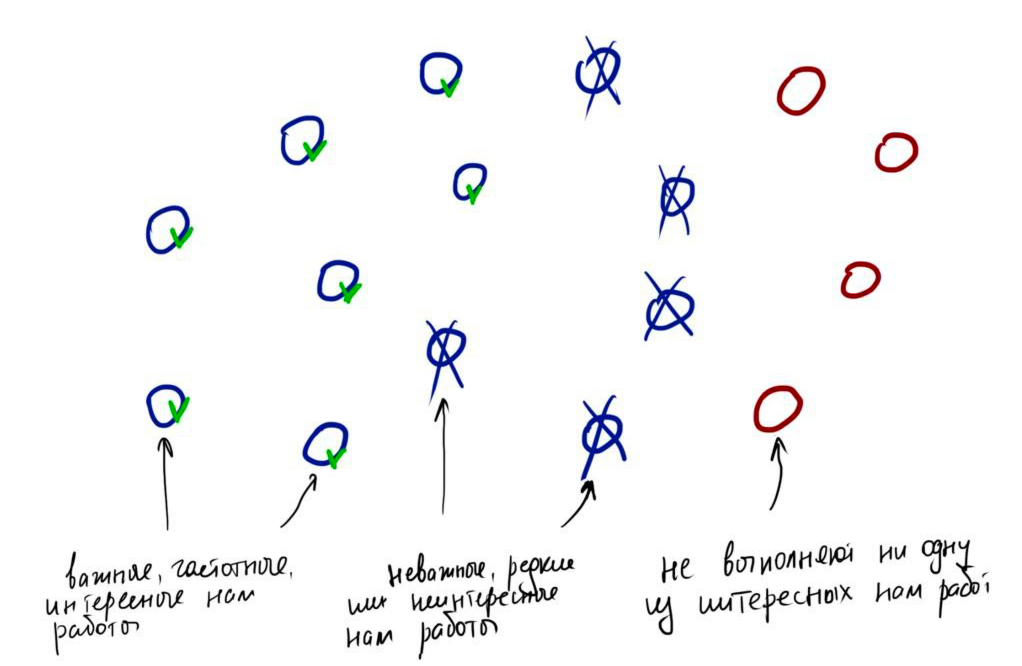
Допустим, из 16 интервью, 7 респондентов платят за выполнение работы, выполняют её часто и выполнение работы важно для них. Наш следующий шаг:

Мы внимательно изучаем, склеиваются ли эти респонденты по похожим высокоуровневым сегментам. Если склеиваются—ура! мы постепенно приближаемся к нахождению интересного для нас сегмента.
Во время склейки у нас рождается скорректированная высокоуровневая работа, добавляются дополнительные квалифицирующие факторы, с помощью которых мы точнее будем находить новых респондентов и в будущем клиентов для продажи. Пример уточнённой высокоуровневой работы с квалифицирующими факторами. Курсив—уточнения:
- когда у меня семья с детьми и наш семейный доход >400 000 руб./мес
- хочу >60 дней в году жить с семьёй ближе к природе и при этом не заниматься хозяйством дома
- чтобы отдыхать от города, лучше восстанавливаться на выходных и больше времени проводить с семьёй и друзьями
Финальная итерация: нашли всех целевых и изучили под микроскопом
После того, как мы скорректировали высокоуровневую работу, мы находим +8 [к исходным 7 респондентам из предыдущей итерации] и проводим с ними оставшиеся JTBD-интервью для поиска сегмента.
Как мы анализируем интервью с ними и выбираем сегмент читайте в следующей главе.